 |
| My Polish travels Spring 2012 |
Whilst completing this post I learnt of the death of a dear friend of many years, Prof. Dr. hab. Jacek Hennel, who died aet 88 on 2nd June 2014.
In the Spring of 2012 I spent just over two weeks in Poland: the main aim was to attend my cousin's wedding in Lubartow. Poland is a country I've always been about to visit, so I made sure to extend my trip. SteveC's
OSM ready for prime-time blog post, prompted to finish this article because 2 years ago I successfully used lots of OSM-based data for my Polish trip.
This really should be about how Poland, Polishness and Poles have always impinged on my life: and why visiting Poland was bound to be imbued with lots of personal meaning. However, to do justice to the subject would just take too long, so what follows is just impressionistic.
Background
I have known Poles all my life:
- One of my father's closest colleagues was a Polish physicist (see above, and below);
- On my first day at school a neglectful parent forgot to collect me at the end of the day and I was consoled by a thoughtful Polish ice-cream man. He was one of many expatriate Poles, Ukrainians, Latvians and other Balts who had been placed in a refugee camp after WWII, at Ruddington, outside Nottingham.
- Others were parents of children in my class at school.
- Some of my closest friends at University had Polish fathers, many of whom had fought in WWII, and, usually, Irish catholic mothers. I will always remember one friend's father, saying in passing through the room when we were watching the end of Oh! What a Lovely War on TV: "There were lots of poppies on Monte Cassino in the Spring".
- A fellow student spent a summer in Gdansk and married a Polish girl he met there.
- My cousin married one (see below).
- There was even a Brighton-based punk band with a partially Polish name.
After graduating I worked in a lab with strong connections to a Warsaw research group: a fellow student spent 3 months in
Tarkovski's lab in Warsaw: his brother was attending the Warsaw Conservatoire at the same time. When martial law was declared I knew people who were put in prison or had to leave Poland by clandestine means: I refused to speak to the Russian in our department at the time.
Man of Iron and
Man of Marble spoke strongly to me, but not just as wonderful films, but because they represented a new hope for Europe arising from Poland. (I still remember my annoyance on leaving the
Academy Cinema on Oxford Street, and overhearing some contemptuous remark about the cinematography.)
Later I lived near Ealing which has a
vibrant Polish community. Many of my Anglo-Polish friends often resented having atypical fathers, with eccentric habits like making sauerkraut and raising ducklings for the pot, and of course, in general not just being embarrassing in the way parents usually are, but being embarrasingly different. However, in Ealing people of my own age seemed very comfortable with both British and Polish heritages.
Krakow
Of course Krakow is a jewel of a city, a heart of Polish culture, (and the destination of choice for
British Stag parties).
My reason for visiting was to meet Jacek and his wife
Jozefa: I've known Jacek as long as I've lived. They are prominent liberal catholic intellectuals who have led lives of extraordinary change, under four completely different political systems: pre-war Poland, the Nazis of
General-Gouvernment, the Soviet puppet communist regime, and modern Poland of the EU.
At supper in the old Jewish quarter of
Kasimierz, Agnieska, Jacek's daughter joined us. I remember going shopping for Beatles records with her when she stayed with my family in the early 70s. She still likes The Beatles. A little later around 1974 she gave me
Enigmatic, an album by
Czesław Niemen.
On the Sunday I visited them at home, and I bought flowers for Jozefa on the Rynek. I was able to enjoy the beautiful scent as I carried them on the tram. Later Jacek told me about his father filming him and his brother with an early 8mm cine camera on the same square before WWII.
High Tatra
 |
| Early morning view of Kunice and the High Tatra |
Another place I had to visit was
Zakopane: my father first went there in the early 60s; and, as a child, I had a promise that I would be taught to ski there. Jacek's aunt remembered seeing V.I. Lenin in the village of
Poronin just before WWI: it was conveniently close to the border for
Lenin to retain contact with revolutionaries within Russia.
Unfortunately I ended up visiting Zakopane at the start of May when two national holidays run into one another. This meant that I could not get the cable car to
the peak of Kasprowy Wierch : the queues were already vast by 07:30, and the town was very crowded.
On the other hand I saw Zakopane as a uniquely Polish resort. A lot was quite vulgar: lots of eating and drinking; and yet the town has the typical faded allure of a 19th Century spa town too. Of course it's real strength is it's presence at the foot of the mountains, and although the main paths were busy this was not unpleasant. I hiked up to a big hut just on the snowline reaching it just before a sharp shower of rain. Most of the way I was passed and passed a group of young Polish women who were celebrating their graduation (one had her treasured certificate with her). They kindly made space for me at their table in the hut. The highlight of the walk was seeing (and photographing) a very sluggish Adder which had just come out of hibernation.
 |
| Sleepy Adder in the Tatra |
Somewhere I have a photo of my Dad outside this same hut in the early '60s.
The rain meant I started back later than planned: I got a bit worried that I wouldn't be out of the Spruce forest before dark, and I had noted the signs about bears too:
 |
| The point when I wished I understood more Polish |
Lubartów, Nałęczów, Lublin and
Kozłówka:
I returned to Krakow to meet other members of my family and do some proper tourism. On the day of the wedding we drove to Lubartów, stopping for lunch at, another slightly faded spa town,
Nałęczów.
Jacek and Jozefa were by now taking a cure and staying at a sanatorium here. This was the only chance for my siblings to see them. I met Jacek in the hall of the sanatorium: he was amazed that we had found it so easily (OSM of course) and we then took a walk in the park and took the waters before returning to see Jozefa. We then adjourned for lunch at the very pleasant restaurant
Ewelina in a villa slightly away from the centre of the spa, with some literary associations with
Bolesław Prus.
 |
Taking the waters at Nałęczów
Jacek Hennel, with the author (right) and his siblings. |
We still had to make it to
Lubartów, which we did comfortably in time for the wedding, although changing was a bit complicated as none of us were actually staying in Lubartów. The wedding itself was not particularly traditional: it was conducted in French and the initial music was provided by Breton
bagpipes and
bombard. There was much cross-cultural interchange on the music front as the church organist learnt some of the traditional Breton tunes, and the Bretons joined in the interminable renditions of
Sto lat over the following 24 hours.
I got to my bed around 4 in the morning in a little country inn at
Kozłówka to the W of Lubartow. As we arrived I heard the wonderful song of a
Golden Oriole from the park across the road. I pottered about the courtyard of the inn the following morning before we resumed eating and drinking in Polish style for the rest of the afternoon and early evening.
 |
Kozłówka Palace, garden front
CC-BY-SA Wikimedia Commons |
I was completely unaware that the park across the road contained a fine palace,
Kozłówka Palace, which I could have visited that morning. Instead I only found it the following day, a Monday, when, unfortunately, it was closed. I'd returned to Kozłówka after I went into Lublin to collect my hire car. In the short time available I was able to walk through the historic centre of Lublin, from the Castle to the Krakow gate passing by the court house in the main square. There are numerous other historic monuments in Lublin given its central role in the establishment of the Polish-Lithuanian Union at the Treaty of Lublin.
Biebrza
The rest of my trip was devoted to visiting a couple more National Parks in search of wildlife. I started by heading North staying the night on the outskirts of
Białyostok to the
Biebrza National Park. I first became aware of this in
a programme made by Bill Oddie for the BBC, and had subsequently met his guide
Marek Borkowski at the Rutland
Bird Fair.
The Biebrza area is a huge (over 2000 km2) area of wetlands stretching along the river Biebrza to its junction with the . At the centre of the area, and the base for the administration of the National Park, is the former fortress of
Osweic, parts of which are still under military control. The fortress was built when this part of Poland was in the Russian Empire. It controlled a strategic crossing of the marshes with a road and railway line, and was relatively close the frontier of East Prussia prior to WWI.
 |
| Female Elk (Moose to N. Americans) at dawn. |
The problem of wildlife watching in early May is that the key times are dawn and dusk which makes for very long days. One of the highlights of the Biebrza marshes is that it still contains a decent population of
Aquatic Warblers (
Acrocephalus paludicola). This bird is now classified as
vulnerable by BirdLife International. The favoured place for seeing them was a boardwalk in the S part of the reserve which was about 20-25 minutes drive from my hotel. This led out into an area of marshland full of the flowers of
Bog Bean (
Menyanthes trifolia). One morning I was lucky enough to see three Elk from an observation tower a little way N of this boardwalk. The drive back after dark brought another nice find:
Hawfinches feeding on the road. My last day I moved over to the N side of the marshes and visited, all too briefly, an area known as the
Red Marsh (
Czerwone Bagno). I met some other birders as I returned and we lamented the absence of many warblers.
Białowieża
Białowieża was my last wildlife destination. I really hoped to see
European Bison in the wild, and I used a guide for an exhausting 6 hour trip starting at 3:45. Ultimately we were unsuccessful, but I did see many Woodpeckers, and a male Citrine Wagtail. I was also very shocked when pulled over by the police at about 5:30 in the morning (they actually turned out to be the Border Guard), and took a long time to find all the documents. I really thought I was in trouble despite my guide's re-assurances. (Later I got stopped again, but was well prepared: the moral is that if you go within 2-3 kilometres of a Border Guard barracks in a car with plates from out of the area expect to be stopped).
Using a guide meant that I now knew the places where I might find Bison. I visited these morning and evening but still failed. Therefore I had to see them in the little zoo close to Białowieża. Walking from the car park to the entrance I got a great view of a
Black Woodpecker which flew up to a nest hole. Whilst watching it a guy accosted me asking if I was interested in any guiding. After a brief conversation I realised that he was Mateusz, the son of
my guide Arek, and he realised that I was the English guy staying in
Siolo Budy. He had noticed this nest at the same time as me.
 |
Black Woodpecker at nest hole
the tree is probably Aspen (Populus tremula) |
I found it amusing that in a few days I had encountered most of the professional guides in Poland.
This part of Poland is great for wildlife, but it doesn't have quite the infrastructure or the number of visitors which would make it easier to get the most out of it. There are plenty of places to stay, but to my surprise most guests were Poles taking weekend breaks (as can be seen by the language of reviews on Trip Advisor and Booking.com). The small number of birders, mostly in guided parties, meant that there was little opportunity to learn about things by word of mouth. This latter contrasts strongly with
Montfraqüe in Spain where the number of birders is not enormous, but in most viewing locations there were other people which increases the chances of catching unusual species without a guide.
Tatar Country
Another aspect of Eastern Poland which I only learnt about when planning the trip, was the existence of a few villages which still perpetuate a distinct
Tatar culture. These are situated to the NE of Bialystok, which itself is probably where most Poles of Tatar descent live. I managed to visit one late in the afternoon when I'd given up on bird-watching because of the rain. Fortunately the mosque was still open even though it was about 6 in the evening, where I was welcomed by a young couple, and given a tour of the mosque (image below), by the man who had a cousin living in Chesterfield!
This area was fairly remote, the main road into the village from the Bialyostok - Brest highway was unsurfaced: a strange contrast after having driven past kilometres of tail-to-tail trucks queuing up for the border crossing into Belarus.
I also wandered around the graveyard a few hundred metres from the mosque: a very pleasant wooded area with a number of active woodpeckers. Many of the gravestones had both Polish and Arabic inscriptions, and to my surprise many had photographs of the deceased on them. I took some photos of these, but don't want to upset any religious sensibilities by posting them here.
Remnants of the Russian Empire
Through Eastern Poland I kept coming across reminders that this area had once been part of the Russian Empire. A road I drove regularly early in the morning before dawn and aeach evening after dusk in Biebrza was known as the Tsar's road. Osweic was an immense Russian-era fortification. Even churches were different because people belonged to different confessions: with both
Uniate and Orthodox churches still common.
It was Białowieża which had been a hunting estate of the Tsars for several centuries where the former Russian influence was most obvious. The Tsar's hunting lodge has gone, but the formal park is still there. Throughout the forest area the rides are spaced at an interval of one
verst with little marker posts at each corner.
 |
| Forest compartment marker, Białowieża |
No doubt there were many other survivals and markers of the hundred or so years when this part of Poland was Russian which I missed.
Being an OSM User
Now I've not said a word about maps so far.
I actually travelled over 2000 kilometers by car, used buses, hiked trails in 3 national parks and wandered around a couple of cities and several towns. I used OSM exclusively for this, with one exception. In the main I used OSM on a Garmin device and used Navit on an Android smartphone. The latter was great, but as I didnt have an in-car charger not useful for long journeys. Instead I relied on the Garmin's beeps for upcoming turns. In the whole time I found a single trail and one linking road of poor quality E of Bialyostok missing.
 |
Early morning ferry across the San at Czekaj Pniowski E of Sandomierz
(I was totally alarmed to see a ferry symbol on a sign, so was very relieved to find such a simple low-key affair.
I was totally reliant on OSM routing at this point.) |
Most of the places I stayed were on OSM, but relatively few POIs such as shops, fire stations and churches. I think a lot of the data came from imports and was subsequently lost at the licence change. Some of it was clearly out of date: in Lubartow the station has been closed for years and buses stop on the main street, not in the location marked as the bus station.
I did no conscious mapping whilst I was there: I had too many other things to do. I did however keep traces and took many geolocated photos.
What I did do 2 years ago was to navigate entirely using OSM across a broad range of Polish landscapes with no serious difficulties.
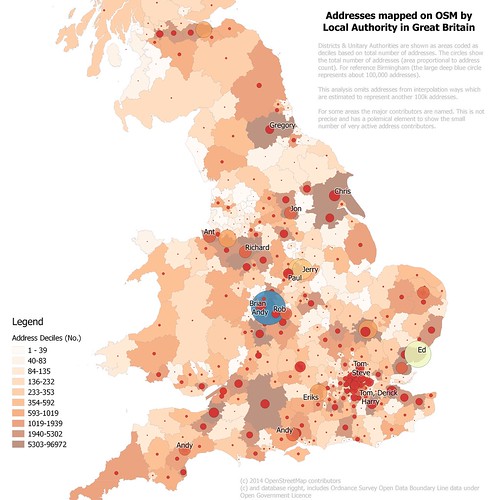
A lot of this OSM data was removed at the time of the license change, but the vast majority was restored by the concerted efforts of many mappers (see
talk by
Marek Kleciak at SotM Baltics). Places like Krakow and Lublin have good quality data, particularly in the old centres, but smaller towns which I visited like Lubartow, Goniadz, and Monki are seriously deficient in POIs. Even a popular tourist centre like Zakopane could do with more on the ground mapping (not least of the seriously good purveyor of cheesecake "Samanta" which has
several outlets in Zakopane).
Coda
A couple of weeks ago I returned very briefly to Krakow for the funeral of Jacek Hennel. The experience really emphasised why Poland has always been, and always will be, a country with emotional significance for me.


.png)



.png)
.jpg)

.jpg)













{kind=link}